The Startup CTO: From Seed Stage to Exit
Startup CTOs often find themselves bombarded with well-intentioned advice, but the truth is, much of it misses the mark. As…
Startup CTOs often find themselves bombarded with well-intentioned advice, but the truth is, much of it misses the mark. As…
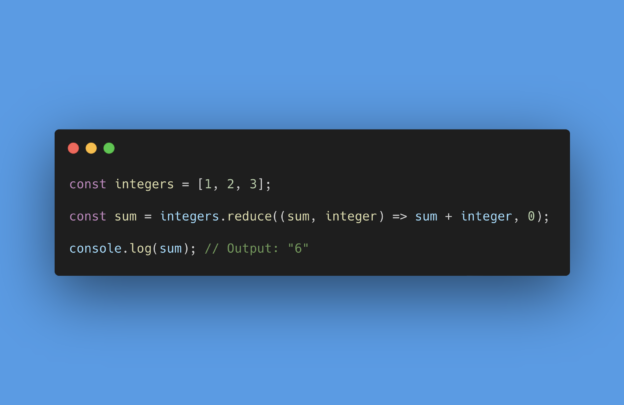
This post shows common use cases for reduce in TypeScript. The examples include how to imitate SQL’s aggregate functions, such…
The basic idea of the Array.prototype.reduce() function is to reduce an array to a single value. For example, reduce an…
This website uses cookies. By continuing to use this site, you accept our use of cookies.